Lakehouse Sharing
(Table Format Agnostic Sharing )

I have worked on this framework or Proof of Concept for two to three weeks, spending nearly an hour each day. And Finally, I am excited about sharing this framework with all of you! The expected outcome of this Article is to understand what lakehouse-sharing is, its Major use cases, Adaptability, and underlying details of this framework (A deep dive into implementation and challenges), and finally future roadmap.
Disclaimer: I am a firm believer that software quality is directly proportional to the number of hours spent on that software combined with a lot of healthy code reviews from peers. Since this particular framework was in an alpha state (Made up of a Single person’s Love). please expect some bugs ahead !!.
Agenda:
Introduction
Common misconceptions about sharing
Lakehouse-sharing
Protocol Deep Dive
The architecture of the framework
Practical setup of the Framework (backend)
Code Overview
under the hood details
Frontend setup and walkthrough
video walkthrough
Querying with the client
conclusion
What is Lakehouse-sharing?
First of all, What is Lakehouse, Lakehouse is a popular storage mechanism and is equally adopted by a lot of companies nowadays. And is a great deal for startups and companies trying to adopt mature big data stacks with low-cost compute and storage separated patterns. we can find more details about the Lakehouse on the internet or ask our new colleague ChatGPT.
So what is Lakehouse sharing, this is completely inspired by or partially Work in Progress implementation of the Delta-sharing protocol in python. This Delta-sharing protocol was developed and open-sourced by Databricks which solves the data-sharing problems securely and easily. You will be able to see Delta-sharing clients in most of the Data Apps. and if you are interested to know more about how delta-sharing solves real-world problems, refer to this blog post
Delta-sharing definition from the words of the official website.
Delta Sharing is the industry’s first open protocol for secure data sharing, making it simple to share data with other organizations regardless of which computing platforms they use.

To further describe this framework or protocol, let’s deep dive into the underlying pattern behind this, I have observed a pattern in companies and organizations, where Developers (business entity or Team) will not be allowed to spin up the resources needed for their work directly in AWS, instead, they will build a platform/self-service portal around that use case and this will be maintained by Platform team (in specific Data Platform team). This platform builds internal Applications and Tools with all the standardization needed in the organization, Abstracting the underlying resources of the cloud.
we can think of Delta-sharing as one such framework which can be deployed and maintained by the Platform team for other teams. without that framework, Each team to get the data from another team (basically other Cloud Account’s bucket) needs to tweak a lot of things on the infra side. Like adding required ACLs in S3 buckets, and adding trust relationships in the IAM roles associated with the account. Trust me debugging the issues in these settings combined with Distributed Systems is horrible and will give you many sleepless nights.
And when the company wants to share the data outside the organization, real challenges begin there. Infra, Compliance, Governance, Security team, and Data Quality Team all need to verify and sign the agreement to share the data.
Enter Delta-sharing protocol, this protocol frees the company from all this underlying time-consuming work and at least reduces a few of this work. let’s see how in this article.
Common misconceptions & difficulties about Delta-sharing protocol.
Few Tech Companies are so concerned about adopting this framework in their data stack, thinking that it will be against their vendor-agnostic design goals and also it will be more tied towards the Delta-lake Table format.
Misconception: In case the Data stack needs to be moved/migrated from one table format to another table format this sharing principle may not work for the other one.
This is strong misconception because Delta-sharing framework is a just Rest protocol on top of Table formats which can be extended to other lakehouse table formats like Iceberg and Hudi. and Even if you have some logical grouping on top of parquet files, you can adopt this protocol and share the data
Why do we need Delta-sharing if we can query the data from lakehouse storage directly?
To avoid some permission-related infra issues and security issues, standardize the data sharing across and outside the Org.
Lakehouse Sharing:
To disprove the above misconceptions, Lakehouse sharing is a humble Proof of concept that demonstrates a Table format agnostic Data sharing Server implemented in python.
Currently, it supports Delta-lake and Iceberg table formats.
This Lakehouse-sharing is implemented in FastAPI (heavily inspired by Delta-sharing scala code base) and this can be easily deployed as a python microservice.
Batteries are included, which means Open-source Delta-sharing does not support full-fledged authentication. This Lakehouse sharing implements this Authentication and Admin interface on top of the delta-sharing protocol.
Also implemented Streamlit UI interface to demonstrate these capabilities
Protocol Deep Dive:
The delta-sharing team (initially Databricks team, now Open source community ) did a great job describing the Delta-sharing protocol in detail in the GitHub Repo. Refer here: protocol specifications. This protocol defines a standard interface to provide a table, column, schema, and metadata information.
Unlike Hive which stores a directory of parquet files in its RDS metadata layer and Query engines implement the file listing and getting the needed files based on stats present in the metastore. All three table formats (Hudi, Delta, Iceberg) evolved from Hive and store the list of parquet files in the metadata layer usually stored along with the data files in the Cloud storage like s3, Adfs, GCS, etc. Benefits and the key difference between hive and table formats are behind the scope of this article.
The Point is, we get the metadata directly from the table format metadata layer and serve those things via the delta-sharing server.
Most of the things in the specification can be implemented easily in other languages for other table formats as well. Currently, most of the API endpoints specified in the specification were implemented in the Lakeshoue-sharing Repo. But one pending API endpoint is /changes API, which provides CDF files (change data capture) of the table format files. implementing this CDF using the table format’s python client (like delta-rs and PyIceberg) was a little tricky at the moment, so skipped the API endpoint for the current POC level which can be added to the Roadmap list.
The interesting thing about this /changes API endpoint is this can be used by Spark Streaming to read the stream of CDF files by calling the server for every micro-batch and replicate the data in another account easily in near real-time.
Okay, Enough theory, show me the Design and code! I understand, here you go !!!
The architecture of the framework

In this Architecture, team 3 shares the data with other teams, and team 1 and team 2 are recipients of the data.
Steps involved:
Team 3 creates a sharing user for this team 1 and team 2. using some self-service portal or by directly calling the lakehouse-sharing framework API. and sharing these tokens with team 1 and team 2 through some secure communication mechanisms (step 1)
Once Team 1 &2 has the token they can call Lakehouse-sharing Server by attaching the token to the header of the HTTP request. (step 2)
The server checks for authentication and Authorization of a particular server and processes the request. (step 3)
The server either contacts the catalog or directly goes and gets the metadata from the table-format metadata. (step 4 & 4.1)
The server will make use of the metadata and statistics from the table format and signs the cloud storage data files (parquet files), and the returned response adheres to the protocol specification. (step 5 & 6)
This Architecture can be further improved by keeping the server behind the load balancer and maybe packaging this framework as a helm chart and getting it deployed in Kubernetes.
Code Overview :
If You are following until now, you might have understood what the basic setup of this code looks like, please refer code structure and other details in the Repo’s readme.

Modules of Lakehouse-Sharing Framework:
The main component of this framework was Backend and Frontend. (typical app )
The backend app consists of the following modules:
core: This module is the core part of the backend app containing cloud, delta, and iceberg modules. Cloud modules contain functions to sign the cloud storage files (GCFs, S3,adls) with the specified expiration. Delta and Iceberg modules contain functions and classes to get the metadata and data files from lakehouse table formats and sign the data files using the cloud module and return the data in a protocol-compliant way.
DB: This module contains tables, and queries needed for storing & querying the Framework’s metadata-RDS of the lakehouse-sharing server.
routers: This module contains FastAPI routers for /admin, /auth,/delta-sharing.
Securities: This module implements JWT token generations.
Utilities: This module contains validators, exceptions, and pagination utility
models: Contains request and response Pydantic models which fast API loves and integrates well.
To show me the code gang: please refer to this repo: https://github.com/rajagurunath/Lakehouse-Sharing
Setup of the Framework
Minimalistic Makefile is present in the repo which helps us quickly setup the server
Prerequisites: Please ensure that you have sufficient cloud storage permission:
example sufficient s3 permission.
Follow the instructions in the repo’s readme to set up the repo.
For all the Docker uses, docker-compose was also included in the repo. so you are just docker-compose up away to try this framework.
Under the hood details:
If you are still following, you will be able to understand how this backend server was developed. I also thought the same when seeing the neatly documented protocol specification, that the backend FastAPI server can be easily implemented. But after started developing this framework, got an opportunity to learn a lot of new things. please allow me to share a few learnings here:
Cloud Storage Signature:
The real secret sauce of the Sharing framework is Signer, which is used by the server to sign the data (parquet) files with expiration (maximum allowed is 7 days) and send the signed files to the end user, thereby once authenticated with the server, the user can read the data files(parquet) without any cloud authentication.
I have tested this file signer for the AWS S3 bucket, New things learned are:
Different signature versions are available to pre-sign the files present in the cloud storage, one of the signature versions used by default exposes AWS ACCESS_KEY in the presigned URL which may not be accepted and this URL was not working with the existing delta-sharing client as well. List of available signatures, refer here
One such signature which is used by delta-sharing as well as this Lakehouse-sharing is `s3v4`: Reference AWS documentation
Signature creation process

source: AWS docs
Other Learning is that Presigning the S3 URL is completely free in AWS, (actually free in all three cloud storage services I guess) this signing is done on the client side without requesting the AWS APIs - reference stack overflow discussion link.

Pagination:

When the number of rows or size of the response was large, Rest Frameworks usually paginate the response, which attaches, next_page_id, previous_page_id, max_size of the page, etc. there are different types of pagination supported by FastAPI. And also there is an existing and easy-to-integrate pagination library available for FastAPI.
But Delta-sharing Protocol uses next_token pagination, which means this next_token (base64 encoded token) will have the information to get to the next page of the pagination process. this token is just base64 encoded version of next_page_no, share_name,schema_name, table_name.
This next_token pagination is not available in the fastapi_pagination, so I developed this module, thanks to the flexibility/solid interface provided by the fastapi_pagination: link to custom pagination module: this module contains encoding and decoding base64 version of the string: link to the exact code lines
NDjson aka streaming response :
I personally misunderstood two API return responses and made some development mistakes, these two APIs are /metadata and /query API. attached is the screenshot of the response of these APIs from the protocol specifications.


Both APIs describe responses as A sequence of JSON strings with a predefined schema for each JSON wrapper object. Both APIs start with a protocol object, followed by a metadata object and for /query API endpoint, each file changed or present in the table format is sent as a separate JSON file delimited by the new line character.
I made a blunt mistake assuming, that I need to frame a large string consisting of these JSON objects (delimited by ‘\n’) and send this to the client. It was working, but the other part of my brain keeps on saying that this method was not scalable, we are expecting to share a large response here, in fact, this is a larger response than the previous APIs like list share, list schema, list tables, etc.. for that small response itself we are having pagination (discussed above), why we don’t have any pagination for this two APIs. on digging deep into these two APIs’ codebases both in the delta-sharing server and client code found that there is one type of JSON called NdJson which is newline delimited JSON. People are using this ndjson for sharing large numbers of JSON objects, actually delta-lake table format stores the metadata in ndjson format only.
The problem is FastApi doesn’t support returning ndjson yet: GitHub issue. but there is always a hack available, somewhere on the internet saw that Starlette, the underlying framework of the FastAPI can allow producing this type of large number of responses in a streaming fashion. enter a streaming response, all we need to do is prepare an iterator or generator in python and this streaming response streams the result of those iterators to the client with an already established TCP connection.
A normal JSON response gives all JSON objects in a single shot which may not be feasible while querying the table which has no less than 1000 files. so NDJson and streaming response are the best suited for this use case:
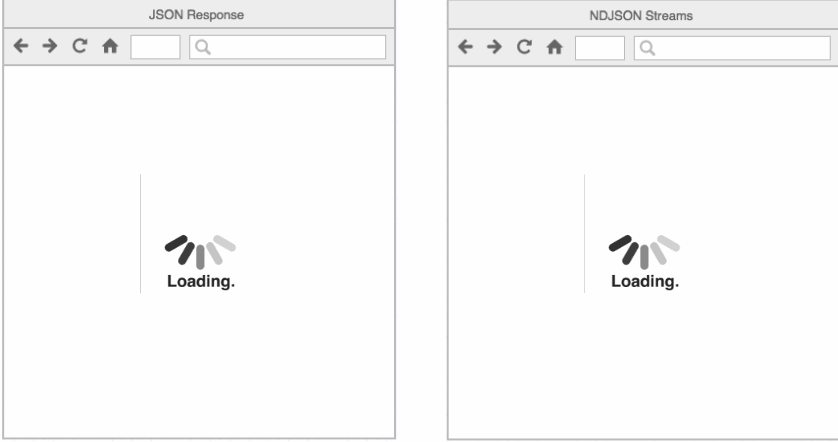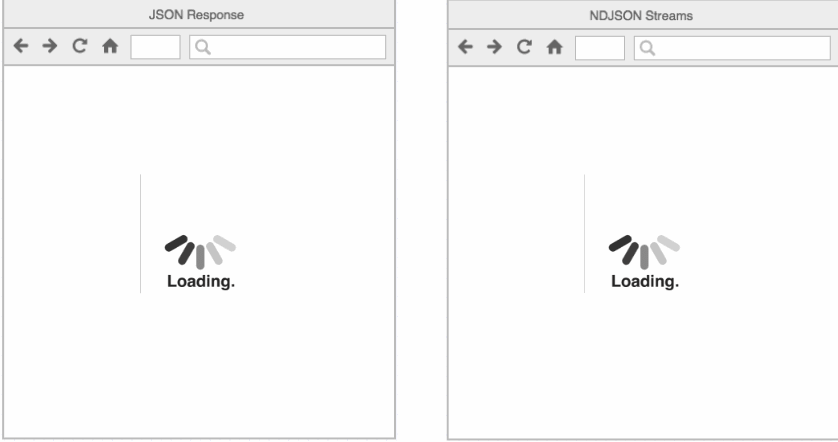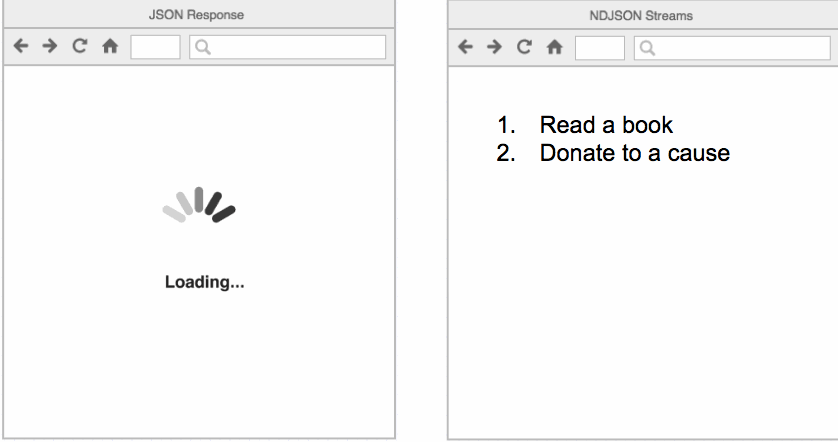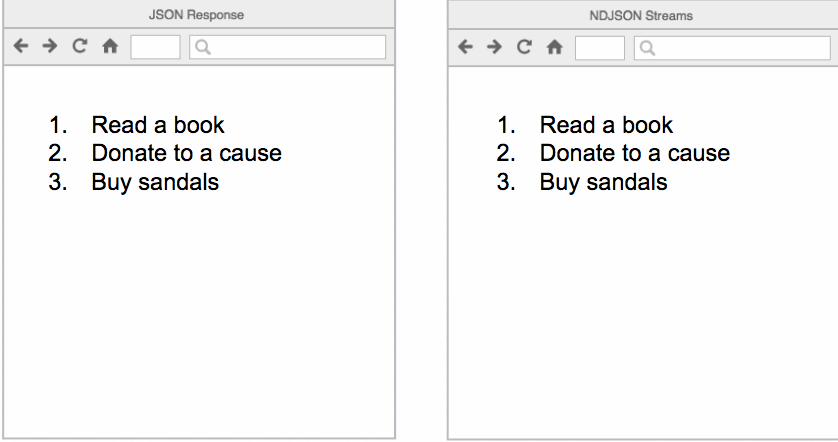
Now I understand why this API was scalable and can easily share a large number of JSON objects effectively in the given small payload limit. so prepared a generator that yields File JSON objects delimited by a newline: here.
Table relationship and design:
The metadata layer of this Lakehouse-sharing can be any sqlalchemy compatible RDS. Open. The Current Open source Delta-sharing server was not using any backend database, they are storing all this information like shares, schemas, and tables in a YAML file.
Designing this table structure was not straightforward, since this is a Quick POC I created these Tables without any constraints, this schema design was in a highly alpha state and even I observed a lot of bugs like duplicates, etc. need to improve this design is one of the major roadmap items.

Currently tested with SQLite and Postgres RDS.
Table format stats :
Getting this Table format stats and processing these stats as protocol complaint response was very straightforward for Delta-lake, since Delta-Sharing was developed on top of delta-lake, it is easy to connect the dots and prepare a server for delta-lake format using python client delta-rs (written on top of rust).

But for iceberg, there are a few hiccups like some stats `maxValues` and `minValues` of the columns are stored in binary format, even I tried converting them back to string but still I am seeing some binary encoded values, need to revisit this behavior and fix this.
Other Learnings:
A few other learnings are like implementing Authentication mechanisms, FastAPI documentation was really helpful for integrating JWT based auth mechanisms. really charged batteries are included in the FastAPI library.
Authorization: Currently this module maintains custom-made simple Authorization mechanisms for each user, maintaining the permission details in the `permission` table. Another scalable and easy alternative available in the python ecosystem was Casbin (available in python as PyCasbin). Planning to add this Casbin-based Authorization (RBAC) mechanisms for this Lakehouse-sharing APP (PR will be raised soon)
And the concept of Chaining dependency, in fact, FastAPI heavily uses Dependency injection for authentication, params validation, etc. chaining this dependency using Depends, makes implementing APIs noise-free (less code) with all the proper validation already in place.
Frontend setup and walkthrough
To show the value of the backend RestAPI built a quick and simple Streamlit APP. which is just a client for this Lakehouse-sharing, offloading all the authentication, admin related activities to the backend server.
As discussed above, the setup should straight forward.
Step 1: if you are using docker, docker-compose up (recommended approach for quick setup). otherwise, if you are adventurous set up the local server based on the installation and readme guide.
Step 2: once the server and DB instance are ready, Run the python script to create and populate the database tables. Sample entry population script was present inside the sqls folder of the root directory
Step 3: Start the backend server after installing the required dependencies (Skip if you are using docker-compose which will take care of this step already)
Step 4: Start the Frontend APP. using the appropriate makefile command. (Skip if you are using docker-compose which will take care of this step already)
Step 5: Log in to the Frontend APP using superuser credentials: (username: admin, password: admin@123)
Step 6: Once Superuser was logged in, he/she can create n number of users and create a logical grouping under one namespace and share that with other teams or organizations.
Video Setup instructions:
Querying with the client:
We can query all the table formats using delta-sharing clients, currently tested with a python delta-sharing client, which expects `Delta-Table-Version` in the headers, we are passing the iceberg snapshot version in the header instead of the delta-table version.
The Example notebook was available in the Github repo here, and how-to instructions for using this client in the notebook are included in the above demo video.
Conclusion
Thanks for reading, In this blog post, we have learned how to implement the delta-sharing protocol in python and also extend this specification for other table formats like Iceberg. Hope this will help a few people who want to explore and extend this Delta-Sharing specification. Please raise any issues or feature requests in the github repo, happy to collaborate and extend this framework.
Once again kudos to the delta-sharing community for the clear specification of the REST protocol considering all Scalability, Authentication, and Authorization dimensions.
Cheers!
Happy Learning!!
Love all!!!